

Natural language processing or NLP is one of the hottest areas of AI today. NLP is a sub-field of artificial intelligence that is focused on enabling computers to understand and process human languages, to get computers closer to a human-level understanding of language.
Computers are great at working with standardized and structured data like database tables and financial records. They are able to process that data much faster than we humans can. But us humans don’t communicate in “structured data” nor do we speak binary! We communicate using words, a form of unstructured data.
Yet our Macs and PCs don’t yet have the same intuitive understanding of natural language that humans do. With NLP algorithms, we can get our machines closer to that deeper human level of understanding language. Today, NLP enables us to build things like chat bots, language translators, and automated systems to recommend you the best Netflix TV shows.
We’re going to take quick dip into the 3 main technical approaches in NLP and how we can use each of them to build awesome machines!
Rule-Based Methods
Rule-based approaches were the earliest types of all AI algorithms. In fact, they dominated computer science as a whole before we thought of automating everything with Machine Learning. The essence of a rule-based algorithm is simple
(1) Define a set of rules which describe all the different aspects of your tasks, in this case language
(2) Specify some sort of order or weight combination of those rules to make a final decision
(3) Apply this formula made up of that fixed set of rules to each and every input in the same way
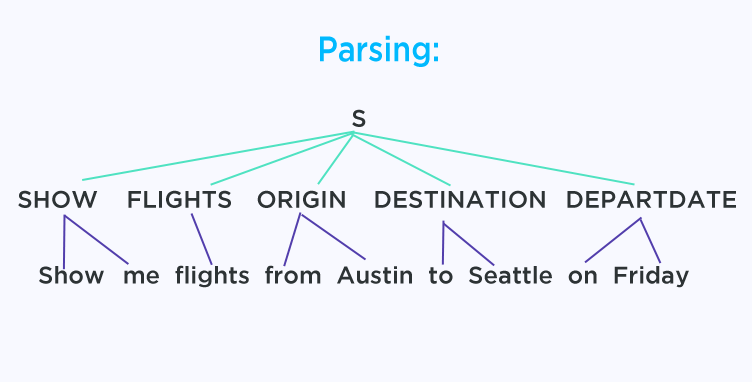
From a human point of view we can easily define a few rules to help a machine understand this sentence:
(1) Anytime we see the word “show” we know that we’ll be doing some visual. So we’ll tag every occurrence of the word “show”, and any other words that are used with it, with the tag SHOW
(2) The word “flights” is a noun; we tag all nouns with the original word. So both “flight” and “flights” will be tagged with FLIGHT
(3) “from” naturally always refers to where something originally came from, so we’ll tag it with ORIGIN. It’s the same idea with “to” which we tag with DESTINATION and “on” which we tag with DEPARTDATE.
Those three rules we just defined allow us to easily understand this sentence!
SHOW = present something visual
FLIGHTS = the thing we want to show
ORIGIN, DESTINATION, DEPARTDATE = all the information we want to show
Rule-based algorithms usually have very high precision since the rules are user-defined. When a human user defines the rules we know that they’re going be correct. The drawback is that such algorithms have very low recall; we couldn’t possibly define every single city in the world! And if for example we forget to put the city of Toronto in our database of cities, then it won’t be detected by our algorithm at all
Classical Machine Learning
Another approach to teaching machines how to understand language is to build a classical machine learning model. The idea is to train a model “end-to-end” with some data that is represented using some user-defined features. Similar to the rule-based approach, such feature design can be quite natural:
- Is the word capitalized?
- Is the word a city?
- What are the previous and next words?
- Is it the first, last, or some middle word in the sentence?
Combining all of this information together would give us a pretty good idea of what a word or phrase actually means.
Since we are training a machine learning model, all of our data will need to be represented as numbers at some point. Capital vs non-capital can be represented as 1.0 and 0.0; the same can be done for city names — 1 and 0 with one-hot encoding over our entire list of cities.
Words are usually represented as some fixed-length vector based on their relation to other words — words that have similar meaning will have similar vectors and vice versa. We can represent the word’s position in the sentence as some integer. It can be categorical (first, middle, last) or open (number of steps from first word in the sentence)
Machine learning models can have higher recall than rule-based models. But in order to achieve high precision their features need to be very well-designed and comprehensive.
Deep Learning
Classical machine learning algorithms can boast high-precision and are relatively easy to implement. But their primary drawback really holds them back: they need feature engineering.
Design features is just plain hard. We understand natural language, well, naturally, but it’s still really hard for us to break it down into concrete steps. We couldn’t possibly think of all of the required rules for understanding language off the top of our head!
With deep learning we don’t have to do any of that complicated feature engineering. The pre-processing will still be roughly the same: transform our text into some kind of vector representation, numbers, that a computer can understand.
But rather than using engineered features to make our calculations, deep learning lets a neural network learn the features on its own. During training, the input is a feature vector of the text and the output is some high-level semantic information such as sentiment, classification, or entity extraction. In the middle of it all, the features that were once hand-designed are now learned by the deep neural net by finding some way to transform the input into the output.
Deep learning models often achieve higher accuracy on large and diverse datasets. However, they may underperform on small datasets or in precision-critical domains where rule-based or hybrid systems remain more effective.
Having knowledge of all of the available tools is always a plus. If a marginal reduction in accuracy is acceptable for your use case, simpler rule-based or classical models may be a more efficient choice—especially when resources or inference speed are a concern. If you really want to squeeze out that last bit of accuracy and have money to spend, go for the heavy weight deep learning!
George Seif is a machine learning engineer and self-proclaimed "certified nerd." Check out more of his work on advanced AI and data science topics.
Frequently Asked Questions
What is natural language processing (NLP)?
NLP is a field of artificial intelligence focused on enabling computers to understand and process human language.
How do rule-based NLP methods work?
They rely on predefined linguistic rules and tags to interpret language. These methods offer high precision but low recall due to their limited coverage.
What are the limitations of rule-based NLP systems?
They struggle with recall and scalability because every scenario must be manually defined, which isn’t feasible for complex or evolving language.


