

Figuring out what people think about a product has never been easier than it is today. Users on social media platforms like Twitter and Facebook provide a great deal of data that companies can use to determine the public’s sentiment about their products. Twitter is a particularly good platform for getting this information since people routinely share opinions on a wide variety of topics and industries. Upon collecting this information, companies can conduct sentiment analysis to make decisions about how to improve their products and services.
Sentiment analysis is an AI-based task that uses natural language processing to understand the feeling, emotion or tone expressed in a text. It has a wide range of applications including stock market predictions, product analysis, social media monitoring and much more.
Collecting text data from Twitter using Python is relatively straightforward thanks to a Twitter wrapper called Tweepy. Upon creating a user developer account, Twitter users can pull data such as their own tweets, tweets of their followers/users they follow and any other tweet that is publicly available. Once you’ve done this, the Python text sentiment library, TextBlob, allows you to easily generate sentiment scores from these tweets.
An interesting application of sentiment analysis is to consider tweets that are related to the COVID vaccines produced by Pfizer, Moderna and Johnson & Johnson. We can perform a simple analysis to compare negative sentiment across these three brands.
Sentiment Analysis
Creating a Twitter Application
To get started with Tweepy, the first thing you need to do is to create a Twitter account if you don’t already have one. Once you have your account set up, you’ll need to apply for a user developer account, which you can do here. You should see the following page:

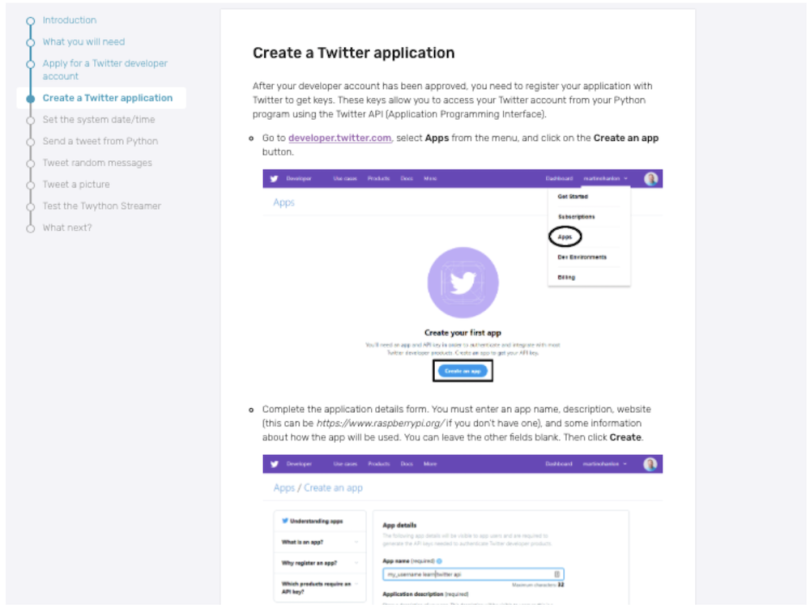
Once you complete the application and it has been approved, you need to create a Twitter application. The steps for doing so are outlined here.
Now that you’ve created the application, you should have generated consumer keys and access tokens. These are strings of random numbers and letters that you’ll use to allow Twitter to authenticate your requests for tweets, without your Twitter username and password. Keep them secret. You can find the steps for accessing your keys and tokens here. You should see the following page:

Authenticating Twitter Access
The next thing you need to do is install the Tweepy package. In a command line, you can run the following command for installation:
pip install tweepy Next, open a Python script and import a few packages that will be useful throughout the tutorial. The Tweepy package will pull tweets, TextBlob will conduct sentiment analysis, the Pandas library will store results in a data frame and Seaborn and Matplotlib will allow for data visualization:
import tweepy
from textblob import TextBlob
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt Next, store your keys and tokens in variables. Note that here I’m using fake keys and tokens. You should use your actual keys and tokens, however:
consumer_key = '5GBi0dCerYpy2jJtkkU3UwqYtgJpRd'
consumer_secret = 'Q88B4BDDAX0dCerYy2jJtkkU3UpwqY'
access_token = 'X0dCerYpwi0dCerYpwy2jJtkkU3U'
access_token_secret = 'kly2pwi0dCerYpjJtdCerYkkU3Um'
Next, authenticate access to your Twitter account by defining an auth object.
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)Now that your access is authenticated, you can define an authenticated instance of a Tweepy object. By passing the auth object into the API method of the Tweepy object, you should be able to access tweets:
api = tweepy.API(auth)
Pulling Tweets Using Tweepy
Now you’re in good shape to start pulling tweets. To do so, you’ll use the Tweepy object’s cursor method. You need to pass in the parameters api.search (to specify that you’re keyword searching), a string keyword and the count for the number of results you’d like to pull.
Loop over the object that the cursor method returned and display the results using a print statement. Pull 1,000 results for the keyword “Pfizer” and also limit results to tweets in English and remove retweets (a truncated screenshot of the output appears below):
for tweet in tweepy.Cursor(api.search,q='Pfizer', count=1000).items(1000):
if (not tweet.retweeted) and ('RT @' not in tweet.text):
if tweet.lang == "en":
print(tweet)
Although this output contains some useful information, it also has a great deal of detail you won’t be using. To only pull tweet texts, you can use the text attribute of each tweet object:
for tweet in tweepy.Cursor(api.search,q='Pfizer', count=1000).items(1000):
if (not tweet.retweeted) and ('RT @' not in tweet.text):
if tweet.lang == "en":
print(tweet.text)
You can also use the created_at and user.name attributes to access the date and time of tweets and the usernames, respectively:
for tweet in tweepy.Cursor(api.search,q='pfizer', count=1000).items(1000):
if (not tweet.retweeted) and ('RT @' not in tweet.text):
if tweet.lang == "en":
print(tweet.text)
print(tweet.user.name)
print(tweet.created_at)Next, initialize lists that will store the values for the dates, usernames and tweets and then append the values to each list:
twitter_users = []
tweet_time = []
tweet_string = []
for tweet in tweepy.Cursor(api.search,q='pfizer', count=1000).items(1000):
if (not tweet.retweeted) and ('RT @' not in tweet.text):
if tweet.lang == "en":
twitter_users.append(tweet.user.name)
tweet_time.append(tweet.created_at)
tweet_string.append(tweet.text)Finally, store this logic in a function that takes a keyword as input and returns a data frame of tweets, dates and usernames. You can then write that dataframe to a csv file using the Pandas to_csv method:
def get_related_tweets(key_word):
twitter_users = []
tweet_time = []
tweet_string = []
for tweet in tweepy.Cursor(api.search,q=key_word, count=1000).items(1000):
if (not tweet.retweeted) and ('RT @' not in tweet.text):
if tweet.lang == "en":
twitter_users.append(tweet.user.name)
tweet_time.append(tweet.created_at)
tweet_string.append(tweet.text)
df = pd.DataFrame({'name':twitter_users, 'time': tweet_time, 'tweet': tweet_string})
df.to_csv(f"{key_word}.csv", index=False)
return df Now you can call your function with the keyword “Pfizer.” This should generate a csv file called “pfizer.csv,” which you can read and store in a data frame:
get_related_tweets('pfizer')
df = pd.read_csv("pfizer.csv")
Now display the first five rows of data:
print(df.head())
The tweet text is appropriately organized in the tweet column. You can now use the TextBlob package to generate sentiment from these tweets.
Sentiment Analysis of Tweets
The Python package TextBlob will generate sentiment scores from this text. It’s a great package for data scientists who are just getting started with natural language processing and sentiment analysis. You can generate sentiment scores with a few lines of code, making the package easy to use. Even better, TextBlob doesn’t require an in-depth understanding of the math behind generating these scores so you can get started fairly easily. Install the package by running the following command in the command line:
pip install textblobTextBlob has a method called sentiment.polarity that generates sentiment scores from negative one to positive one. Negative values correspond to negative emotion, positive values correspond to positive emotion and a value of zero is neutral.
We can apply the sentiment.polarity method from the TextBlob object to the tweet column in our data frame and store the results in a new column called sentiment:
df['sentiment'] = df['tweet'].apply(lambda tweet: TextBlob(tweet).sentiment.polarity)
print(df.head())
To make sentiment score generation more reusable for each keyword, instead of reading in the file, define a function that calls the get_related_tweets function:
def get_sentiment(key_word):
df = get_related_tweets(key_word)
df['sentiment'] = df['tweet'].apply(lambda tweet: TextBlob(tweet).sentiment.polarity)
print(df.head())Now, if you call the function with “Moderna,” you should get a new data frame (as well as the csv file for future use):
get_sentiment('Moderna')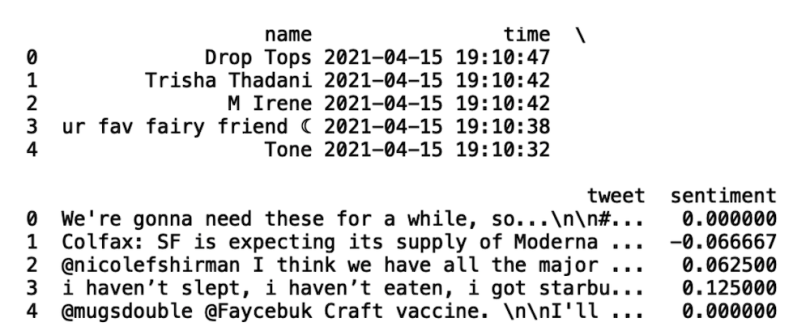
You can count negative and positive sentiment tweets by filtering the data frame according to the value of the sentiment. Create negative and positive sentiment data frames (Note that ‘...’ represents truncated code):
def get_sentiment(key_word):
...
df_pos = df[df['sentiment'] > 0.0]
df_neg = df[df['sentiment'] < 0.0]Pass these data frames into the built-in len() method to count the negative and positive sentiments:
def get_sentiment(key_word):
...
print("Number of Positive Tweets about {}".format(key_word), len(df_pos))
print("Number of Negative Tweets about {}".format(key_word), len(df_neg))
Now, call this function with “Pfizer,” “Moderna” and “Johnson & Johnson”:
get_sentiment('Moderna')
get_sentiment('Pfizer')
get_sentiment('Johnson & Johnson')
Note that this method takes a sample of 1,000 tweets at the time that the script runs. This also removes the counts of neutral tweets.
Finally, visualize the results in bar plots for each brand using Matplotlib and Seaborn:
def get_sentiment(key_word):
...
sns.set()
labels = ['Postive', 'Negative']
heights = [len(df_pos), len(df_neg)]
plt.bar(labels, heights, color = 'navy')
plt.title(key_word)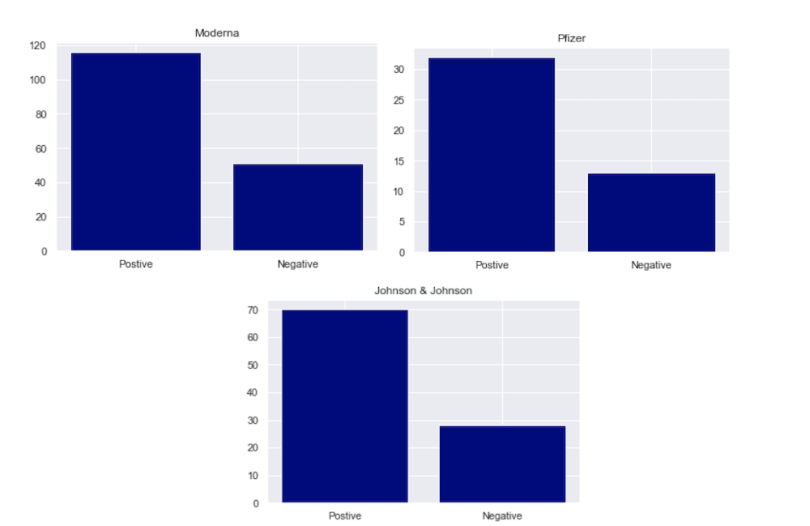
Across all three brands, there are more positive sentiment tweets than negative. Moderna has 43 percent negative sentiment, Pfizer has 28.8 percent negative sentiment and Johnson and Johnson has 28.5 percent negative sentiment.
I’ll stress here that these results aren’t conclusive as they are derived from a relatively small sample size. A collection of a larger corpus of tweets for each brand will surely generate more statistically significant results. Namely, we’d need to increase the sample size to guarantee that these results are not due to chance. Still, we can begin to get a sense of attitudes through this analysis.
Start Analyzing Today
Now that you have the skills to begin sentiment analysis, you can continue to track and refine your results as attitudes toward the vaccines evolve. An interesting analysis would be to collect tweets over the course of several days, weeks or months to see how sentiment changes over time.
Sentiment analysis is a useful way to extract meaningful information about emotion and tone in text. Although in this piece we only considered keywords related to COVID vaccines, the methods outlined here can be applied to any industry vertical where consumer opinions are valuable. For example, anyone interested in stock market analysis could easily pull tweets about Tesla stock and then generate sentiment scores. These scores can then serve as inputs for statistical models that predict the direction of stock price.
The Tweepy package allows Twitter users with some Python savvy to quite easily pull texts about any topic of interest. This data can then easily be structured in a data frame and kept for later use. Further, the TextBlob package allows users to quickly perform sentiment analysis on text, be it tweets or otherwise, without much knowledge of natural language processing. Other methods of generating sentiment scores are very mathematically involved and often inaccessible to those unfamiliar with NLP methods.
The combination of the Tweepy package and TextBlob allows python developers who are just getting started with natural language processing to pull insights from texts in a quick and easy-to-understand manner. In addition to the analysis we performed, users can perform state-level sentiment analysis of each of these keywords. These analyses can uncover interesting sentiment biases at the state level if they exist.
Further, users can collect data for a keyword over time and analyze how sentiment changes in time. A variety of interesting problems can be framed and solved using these tools. Tweepy and TextBlob are invaluable for data scientists getting their feet wet with natural language processing and text analysis.


