

It's an amazing time to be a machine learning engineer or data scientist. So many advanced resources are just a few keyboard clicks away. Powerful pre-trained machine learning models, from translation to image recognition, are publicly available and can be accessed at scale. An enthusiastic newcomer to machine learning, after picking up some basic coding skills on day one, can use models with billions of parameters at the frontier of AI research.
Yet, despite such an abundance of tools, launching a successful AI project is not easy. Many choices need to be made. You need to pick models, algorithms, libraries, signals, platforms — the list goes on. But while AI might now be ubiquitous, it's not always clear how to optimally design and complete an AI project.
Let's imagine the following scenario: You lead your organization's customer success team. Every day, hundreds of customer support tickets come in, overwhelming your limited team capacity. You would like to add an AI layer to the support ticket workflow to prioritize those that are urgent and important, and automate responses when appropriate.
How do you get a project like this off the ground?
3 Guiding Principles to Kick-Start Your AI Initiative
- It's okay to be narrow.
- Plan your AI mistakes.
- Build trust in AI.
It's Okay to Be Narrow
The first rule is start small and narrow. One major goal of AI is general intelligence, an algorithm that can perform many different tasks, just like a human. A lesser version is narrow or weak AI, which is specifically trained to perform a certain task, such as playing chess or detecting credit card fraud.
While narrow AI sounds less appealing, in practice, it can be just the right strategy. Let's return to our support tickets scenario. Each support ticket contains text describing the issue the customer is having, so we need an algorithm that understands text.
But when it comes to our specific task of optimizing the support workflow, it might not be optimal to start with a big, generalist model.
To illustrate why, let's visualize how a language model "thinks" about words. We can ask the model to play the word association game. Given words like "bill" and "freeze," what are the most closely related words?
For a big model, a word like "bill" brings up concepts related to legislation (like “reform,” “amendment,” or “bipartisan”). And "freeze" is generally associated with low temperatures (think “cold,” “chill,” or “thaw”).
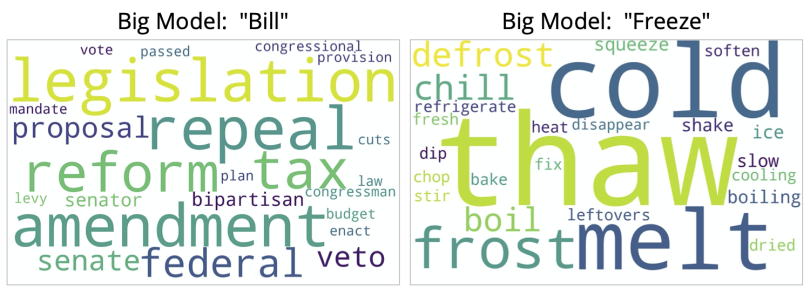
While these word associations are essentially correct, they’re not relevant to our needs.
In the customer support context, "bill" and "freeze" have special meanings. Customers inquire about billing a lot, and one major user issue is a non-responsive interface. Even with a small dataset of less than 100,000 messages, we can train a highly specialized model that "thinks" more along the line of the support context.
For this specialized model, "bill" is associated with billing (like “invoice” or “receipt”), and "freeze" is conceptually linked to a buggy user experience (“close,” “crash,” “quit”).
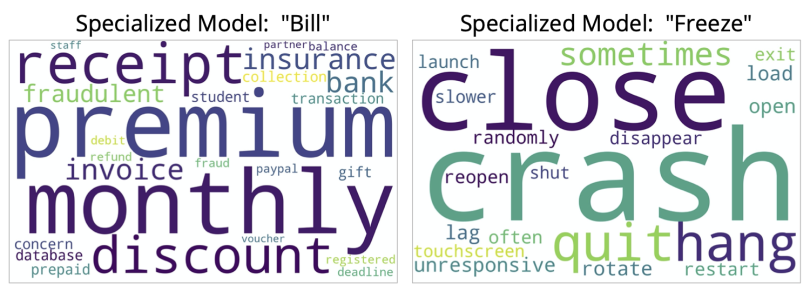
Thus, an AI solution for support tickets can have a faster development cycle when the language model is specifically aware of the support use case.
Plan Your AI Mistakes
No algorithm is perfect. Even the most advanced AI will make mistakes, so AI implementation design should also include how to make mistakes.
Let's continue with the support ticket example. In this project, we propose to have a machine learning model classify each ticket as urgent or non-urgent. In this classification task, the model can be right in two ways: saying a ticket is urgent when it really is urgent, and saying a ticket is not urgent when it is not urgent. And the model can also be wrong in two ways: saying a ticket is urgent when it's not urgent, and saying a ticket is not urgent when it is urgent. You might be familiar with this framework — these four outcomes are the four grids in a confusion matrix.
Data scientists spend a lot of time improving model performance metrics. But the most relevant way of evaluating a model should be business impact. And when it comes to business impact, the balance between precision and recall becomes a lot more nuanced than simply counting mistakes.
For instance, there are two ways of being wrong, yet the cost of each can be very different. Predicting a support ticket is urgent when it's not creates extra burden for the team. On the other hand, predicting a ticket is not urgent when it really is could lower customer satisfaction and increase churn.
Balancing these types of business costs and benefits is a lot more relevant than simply trading precision and recall. In scenarios where taking an action by mistake is too expensive, we might want our algorithm to be stringent — meaning no action is taken unless we are really sure, even if this means missing opportunities.
Build Trust in AI
Imagine you have made tremendous progress with the support ticket AI project. You have gathered lots of data on past tickets, built an algorithm that predicts if a ticket is urgent, and the algorithm also picks the best response out of a few templates. The model works.
But will it be used? How do you embed such an algorithm within the team's workflow?
When designing an AI project, you should consider human-algorithm interaction. One of the most important aspects of an AI project is algorithm effectiveness and usability — an algorithm will not be effective if it is not adopted by users, regardless of model accuracy. Users and human experts can greatly enhance algorithm effectiveness. This could be due to domain knowledge not captured by data, like salespeople who have a personal connection with their customers.
In addition, there is something humans effortlessly do that algorithms cannot (yet) automate. Humans are much better at cause-effect analysis and at coming up with causal explanations. While we are not always right, our mechanistic interpretation — or, simply, common sense — provides us with some defense against spurious correlations, where in a dataset with many variables, some would show correlation merely by chance.
Take this jellybean problem as an example. We’d find the notion that jellybeans are linked to acne absurd, as we can not come up with a plausible mechanistic explanation of such a cause-effect relationship.
So how can we put a human in the middle and build trust between AI and users?
- Choose model algorithms that are easier to interpret, especially those that allow deriving intuitive rules that can be reviewed by an expert (like this expert-augmented model that combines a decision tree algorithm with clinician experts to predict risk of intensive care unit patients).
- Involve humans to translate AI scores and recommendations into snippet explanations. Here's an example: "This support case is urgent because the user is a paying customer for two years, and their product activity has decreased by 50 percent in the last month."
- Have an interactive interface that accepts user inputs and adjusts model behavior on the fly. If a support case is classified to be urgent, for instance, allow a human reviewer to approve or downgrade it.
- Don't expect the algorithm to be static. Constantly incorporate user inputs into continuous learning algorithms (like reinforcement learning) to update the model. For example, the algorithm can detect and learn when human reviewers are consistently downgrading certain support cases classified as urgent.
So remember, it's okay to start small and narrow. Design a specialized algorithm for your specific task, and plan your AI around its anticipated mistakes to maximize business impact. Instead of rounds of parameter tuning to eke out a higher accuracy invest in designing how the algorithm and user interact in a live production system. Hopefully these principles will help kick-start your new AI initiative.


