

Training the algorithms of AI-based systems for autonomous or highly automated driving requires enormous volumes of data to be captured and processed.
These algorithms must be able to master numerous challenges so that self-driving cars can detect all essential details of their environment, make the right decisions and take people safely to their destination.
Every Data Annotation Project Is Large-Scale in Autonomous Driving
Why does training require this much data? AI-based systems enable quick progress, but this progress slows down after a certain point. More and more data is needed to improve the model performance. Moreover, we have to make sure that self-driving systems can reliably handle rare events. Rare event data has a significant impact on the performance of the trained algorithm. Bringing sophisticated AI-based driving functions to the road safely therefore requires a growing amount of higher-quality data.

In general, AI functions in production systems must cross a very high reliability threshold before being used in real systems. In automated driving in particular, the associated safety risks are extremely high. The tragic accidents at Uber and Tesla are admonishing reminders of this. As a consequence, registration authorities require ever stricter validation measures for high-quality driving functions to ensure their correct operation. Since these validation measures are often based on driven kilometers (or miles), they require large volumes of data.

A Feast of Data
The following calculation example will give you an impression of the data volumes that have to be processed to validate a combined radar-and-camera sensor system.
Sensor Setup and Method
For this example, the correct functioning of the sensor system must be demonstrated over a distance of 300,000km with a predefined mix of driving scenarios. The sensor system provides an object list that describes the vehicle’s environment.
To check if the sensor system object list is correct, a comparison list — called “ground truth” — is required. This list is generated using a reference sensor set consisting of a camera and lidar sensor. The reference sensor set is installed in the vehicle as a rooftop box in addition to the sensors to be checked. The data stream of the reference sensor set is transferred to the ground truth object list by means of an annotation process. By systematically comparing the two object lists, deviations are detected and corrective measures can be derived.
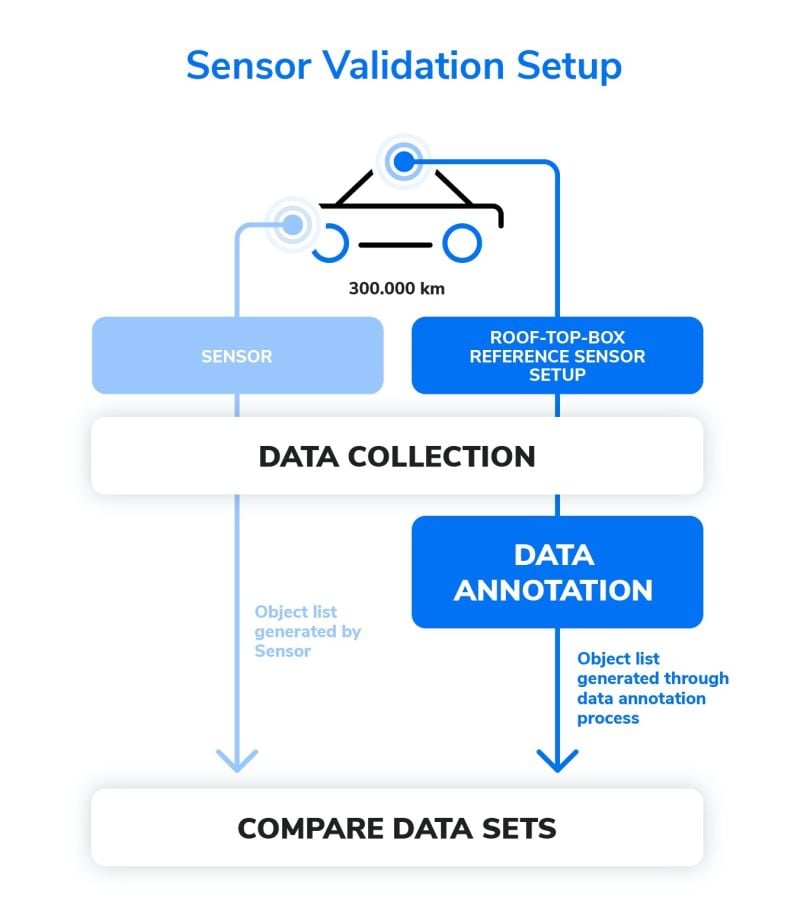
Estimating the Labeling Effort
The estimation of the annotation effort, which is still primarily done by humans, is based on the following assumptions regarding the parameters of the reference sensor setup.
- Lidar frequency: 10 frames/second
- Achieved average speed: 45 km/h
- Average number of objects (vehicles, pedestrians, motorcycles) per frame: 15 objects/frame
Example Calculation of a Validation Project
- Travel time in seconds: 300,000 km / 45 km/h = 6,666 h = 23,997,600 s
- Number of frames: 23,997,600 s * 10 f/s = 239,976,000 f
- Number of objects: 239,976,000 f * 15 o/f = 3,599,640,000 o
This results in an annotation effort of almost 3.6 billion objects.
State-of-the-art systems achieve a throughput of approximately four seconds per object in a 3D space. The time required is measured end-to-end — i.e. across all annotation, review and correction steps, from import to export.
- Time in seconds: 3,599,640,000 o * 4 s/o = 14,398,560,000 s
- Work estimate: 28,797,120,000 s = 3,999,600 h = 499,950 8hr days
- Project duration: 3 years (220 work days each)
- Number of labelers needed: 499,950 d / 660 wd = 757.5 labelers

Assuming a project duration of three years (at 220 working days per year), an annotation team with an average size of approximately 750 people would be required.
It’s a lot!
The challenge lies in providing a data annotation system that is capable of continuously providing 750 people with sufficient work and enabling an average processing time of four seconds per object for the specified target quality — across all employees and skill levels. The average processing time per object must be further reduced before the costs go through the roof. Annotation automation is a key ingredient.
What else needs to be done?
A Data Enrichment Recipe
Collect ingredients, select and prepare your data: To master the challenge fully automatically, several critical process steps must be carried out without media changes.
1. Data Collection
A sufficient number of vehicles must collect data on the road so that the required data volumes can be brought in and made available for further processing. The AUTERA system from dSPACE allows reliable recording of sensor and telemetry data in the vehicle and seamless data transfer.
2. Data Preparation
Before the recorded data can be further processed, it must be anonymized in accordance with the data protection regulation applicable to the respective region. This means that identifying features — such as license plates and faces and sometimes GPS data — must be made unrecognizable.
Ideally, anonymization is fully automated and carried out with sufficient speed so it does not become a bottleneck for the entire project. At Understand.ai, we offer the UAI Anonymizer for this task for this task. It’s a solution that meets these requirements and has proven its reliability in numerous projects.

3. Data Selection
For training projects, sensible data reduction is essential. This means that exactly those scenarios must be selected that offer the greatest learning gain for the algorithms to be trained. This process is relatively simple at the beginning of the development phase, but it gets considerably more difficult over the course of the project.
We’ve shown how the achieved progress slows down significantly after a certain point. At the beginning of the training, many of the recorded scenarios are new for the algorithm or are not yet available in sufficient numbers. Rapid progress is being made at this stage; however, as the algorithms mature, it becomes increasingly challenging to find interesting data. It is then probably possible to record valuable new scenarios only every few thousand kilometers. That’s where sophisticated data selection systems like the Intempora Validation Suite composing good training, validation and test sets step in.
The sparsity of meaningful scenarios per driven kilometer requires ever larger test fleets. The common approach of using dedicated test fleets with their own test drivers becomes the limiting factor at this point. Tesla is going a different way: Thanks to the sensors installed on their cars by default, customers gather data during every ride. This gives Tesla access to an almost unlimited amount of data — including the “rare events” mentioned earlier.
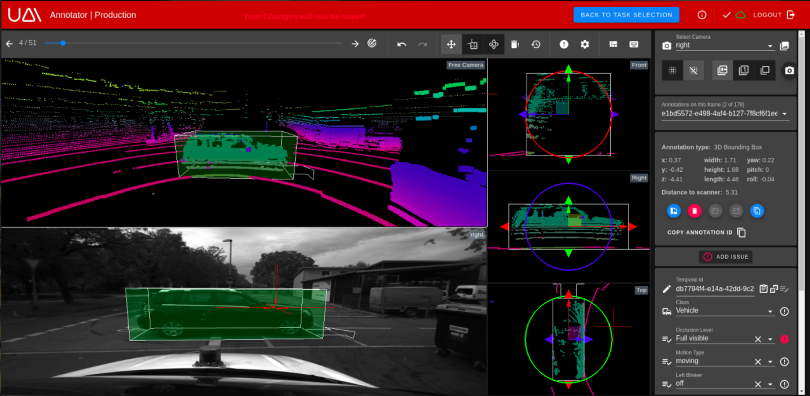
4. Data Annotation
Next, the selected data has to be annotated. We are aiming for high-precision, detailed object lists. Although offline annotation (as opposed to real-time detection in the vehicle while driving) can make use of a variety of tools and state-of-the-art technology with almost unlimited computing power, a relevant piece of the work still has to be done manually. In the above example, even with 95 percent automation, 395,954,000 objects still have to be annotated manually.
A number of different automation strategies are used to reduce the level of manual work as much as possible and to achieve the necessary throughput for the specified quality requirements. Let’s have a look at how our UAI Annotator automates and organizes annotation work.
- Regression: This refers to box tightness — i.e. the accuracy of fit of the annotation. Common labeling requirements assume a tolerance of two to four pixels. Understand.ai uses deep-learning techniques to adjust boxes automatically and precisely.
- Automatic Object Detection: This can help save time in the localization and identification of objects. Especially in a 3D space, localizing objects far away from the sensor with only low lidar coverage can take a long time. However, this technology is not yet robust enough to do without manual review.
- Classification: For certain object properties, such as turn signals, brake lights, traffic signs and more, Understand.ai also uses AI-based systems to save a considerable amount of time and improve quality.
- Model-Based Interpolation, Extrapolation and Propagation: A high degree of automation can be achieved by using interpolation in which only keyframes are annotated manually, but the intermediate frames are annotated automatically. Objects that appear or disappear on intermediate frames are a particular challenge. Standard interpolation methods are not very useful either, because they are too imprecise. Model-based interpolation, extrapolation and propagation methods are one approach to a solution. With these methods, the algorithms learn typical movement patterns for object classes and derive natural movement sequences from them. The interpolation rates can thus be increased significantly.
Properly Organizing Labelers
A crucial component for an annotation project is the workflow management system. Here are the basic needs:
- It must be sufficiently versatile to cover a wide range of project requirements. Understand.ai uses individual modules to create workflows of any complexity. These modules can either result in manual work packages or perform tasks automatically.
- It must be readily available to ensure the permanent flow of data through the annotation production line. Any system downtime would result in idle time for the 750 labeling experts in the example.
- It must have mechanisms to distribute the work to the labeling crew as intelligently as possible. This ensures that the team is working on the right tasks at the right time to move the project forward.
Chef’s Recommendations
Increasingly complex driving functions require more and more sophisticated systems to process the associated wave of data promptly, cost-effectively — and at the highest quality. Sophisticated driving functions can be brought to series production only with the right data in the right quality and quantity. The systems for large-scale data refinement developed by Understand.ai and dSPACE can help master this challenge.


