

Rate limiting refers to preventing the frequency of an operation from exceeding a defined limit. In large-scale systems, rate limiting is commonly used to protect underlying services and resources. Rate limiting is generally used as a defensive mechanism in distributed systems, so that shared resources can maintain availability.
What Is Rate Limiting?
Rate limiting protects your APIs from unintended or malicious overuse by limiting the number of requests that can reach your API in a given period of time. Without rate limiting, any user can bombard your server with requests leading to spikes that starve other users.
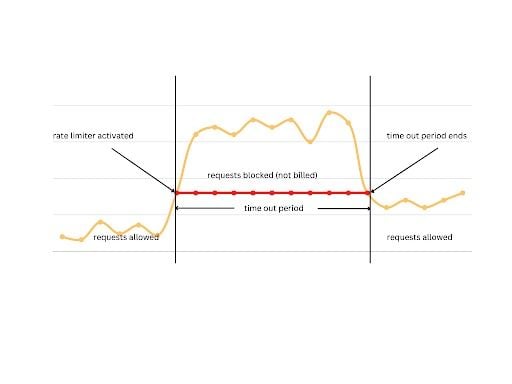
Why Use a Rate Limiter
Below are three reasons to use a rate limiter:
1. Preventing Resource Starvation
The most common reason for rate limiting is to avoid resource starvation and improve the availability of API-based services. Rate limiting can also help you prevent load-based denial of service (DoS) attacks. Other users aren’t starved, even when one user bombards the API with loads of requests.
2. Security
Rate limiting prevents users from brute forcing security intensive functionalities like login, promo codes, etc. The number of requests for each of these features is limited on a user level ensuring that brute force algorithms won’t work in these scenarios.
3. Preventing Operational Costs
In the case of auto-scaling resources on a pay-per-use model, rate limiting puts a virtual cap on the scalping of resources to help control operational costs. Without rate limiting, resources might scale out of proportion leading to exponential bills.
What Are the Different Types of Rate Limiting?
Rate limiting can be applied on the following parameters:
1. User Rate Limiting
A limit is applied on the number of requests allowed for a user in a given period of time. User-based rate limiting is one of the most common and intuitive forms of rate limiting.
2. Concurrency Rate Limiting
Here the limit is employed on the number of parallel sessions that can be allowed for a user in a given timeframe. A limit on the number of parallel connections also helps mitigate distributed denial of service (DDoS) attacks.
3. Location and ID Rate Limiting
This is useful when you’re running location-based or demography-centric campaigns. Requests from outside the target demography can be rate limited so as to increase availability in the target regions.
4. Server Rate Limiting
Server-based rate limiting is a niche strategy. This is generally employed when specific servers need to handle most of the requests, such as servers that are strongly linked to executing specific functions.
Common Rate Limiting Algorithms
5 Common Rate Limiting Algorithms
- Leaky bucket.
- Token bucket.
- Fixed window counter.
- Sliding Log.
- Sliding Window.
1. Leaky Bucket
Leaky bucket is a simple, intuitive algorithm. It creates a queue with a finite capacity. All requests in a given time frame beyond the capacity of the queue are spilled off.
The advantage of this algorithm is that it smoothes out bursts of requests and processes them at a constant rate. It’s also easy to implement on a load balancer and is memory efficient for each user. A constant, near-uniform flow is applied to the server irrespective of the number of requests.
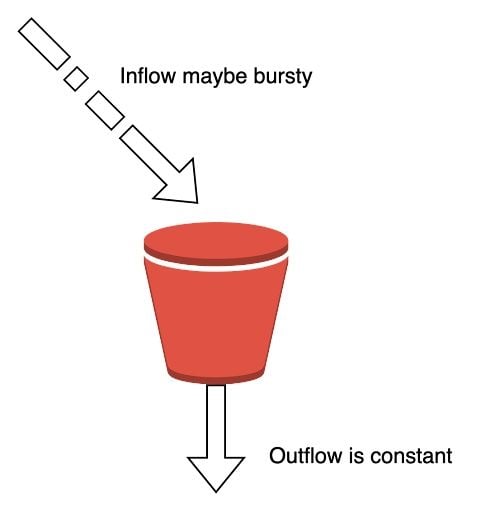
The downside of this algorithm is that a burst of requests can fill up the bucket leading to the starvation of new requests. It also provides no guarantee that requests get completed in a given amount of time.
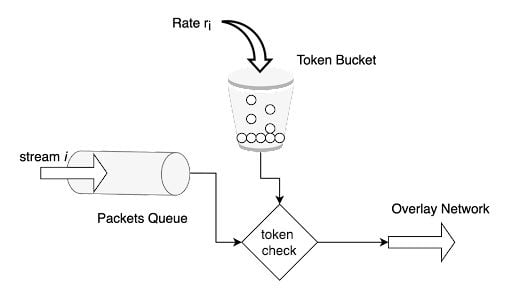
2. Token Bucket
The token bucket algorithm is similar to leaky bucket, but instead, we assign tokens on a user level. For a given time duration d, the number of request r packets that a user can receive is defined. Every time a new request arrives at a server, there are two operations that happen:
- Fetch token: The current number of tokens for that user is fetched. If it is greater than the limit defined, then the request is dropped.
- Update token: If the fetched token is less than the limit for the time duration d, then the request is accepted and the token is appended.
This algorithm is memory efficient because we are saving less data per user for our application. The problem is that it can cause race conditions in a distributed environment. This happens when there are two requests from two different application servers trying to fetch the token at the same time.
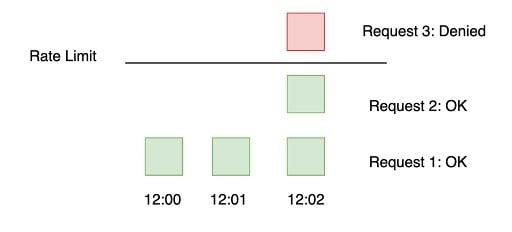
3. Fixed Window Counter
Fixed window is one of the most basic rate limiting mechanisms. We keep a counter for a given duration of time and continue incrementing it for every request we get. Once the limit is reached, we drop all further requests until the time duration is reset.
The advantage is that it ensures that the most recent requests are served without being starved by old requests. However, a single burst of traffic right at the edge of the limit might hoard all the available slots for both the current and next time slot. Consumers might bombard the server at the edge in an attempt to maximize the number of requests served.
4. Sliding Log
A sliding log algorithm involves maintaining a time stamped log of requests at the user level. The system keeps these requests time sorted in a set or a table. It discards all requests with timestamps beyond a specified threshold. Every minute we look out for older requests and filter them out. Then we calculate the sum of logs to determine the request rate. If the request would exceed the threshold rate, then it is held. Otherwise, the request is served.
The advantage is that it does not suffer from the boundary conditions of fixed windows. Enforcement of the rate limit will remain precise. Since the system tracks the sliding log for each consumer, you don’t have the stampede effect that challenges fixed windows.
However, it can be costly to store an unlimited number of logs for every request. It’s also expensive to compute because each request requires calculating a summation over the consumer’s prior requests, potentially across a cluster of servers. As a result, it does not scale well enough to handle large bursts of traffic or denial of service attacks.
5. Sliding Window
This is similar to the sliding log algorithm, but it’s more memory efficient. It combines the fixed window algorithm’s low processing cost and the sliding log’s improved boundary conditions.
With this algorithm, we keep a list/table of time sorted entries, each being a hybrid and containing the timestamp and the number of requests at that point. We keep a sliding window of our time duration and only service requests in our window for the given rate. If the sum of counters is more than the given rate of the limiter, then we take only the first sum of entries equal to the rate limit.
The sliding window approach is the best because it gives you the flexibility to scale rate limiting while still maintaining good performance. The rate windows are an intuitive way to present rate limit data to API consumers. It also avoids the starvation problem of the leaky bucket and the bursting problems of fixed window implementations.
How to Apply a Rate Limiter in Distributed Systems
While those algorithms work well for single server applications, it’s a lot more complicated when there’s a distributed system with multiple nodes or app servers. When there are multiple rate limited services distributed across different server regions, two problems arise: Inconsistency and race conditions.
Inconsistency
When you have complex systems with multiple app servers distributed across different regions each with their own rate limiters, you need to define a global rate limiter.
A consumer could surpass the global rate limiter individually if it receives a lot of requests in a small time frame. The greater the number of nodes, the more likely the user will exceed the global limit.
There are two ways to solve for this problem:
- Sticky session: When you introduce a sticky session in your load balancers, each consumer gets sent to exactly one node. The downside to this strategy includes a lack of fault tolerance and scaling problems when nodes get overloaded.
- Centralized data store: You can use a centralized data store like Redis or Cassandra to handle counts for each window and consumer. While this adds latency, the flexibility it provides makes it an elegant solution.
Race Conditions
Race conditions happen in a get-then-set approach with high concurrency. Each request gets the value of the counter then tries to increment it. But by the time that write operation is completed, several other requests have read the value of the counter, which is not correct. As a result, a larger number of requests are sent than what was intended. This can be mitigated using locks on the read-write operation, thus making it atomic. But this comes at a performance cost as it creates a bottleneck causing more latency.
Throttling
Throttling is the process of controlling the usage of the APIs by customers during a given period. Throttling can be defined at the application level and/or the API level. When a throttle limit is crossed, the server returns HTTP status “429 — Too many requests.”
There are three types of throttling:
- Hard throttling: The number of API requests cannot exceed the throttle limit.
- Soft throttling: In this type, we can set the API request limit to exceed a certain percentage. For example, if we have a rate limit of 100 messages a minute and a 10 percent exceed limit, our rate limiter will allow up to 110 messages per minute.
- Elastic or dynamic throttling: Under elastic throttling, the number of requests can go beyond the threshold if the system has some resources available. For example, if a user is allowed only 100 messages a minute, we can let the user send more than 100 messages a minute when there are free resources available in the system.
Frequently Asked Questions
What is a rate limiter?
A rate limiter is a mechanism that limits the number of requests sent to an API over a set time to prevent overuse and server strain.
Why is rate limiting important?
Rate limiting helps prevent resource starvation, defends against denial of service (DOS) attacks, enhances security and controls operational costs.
What are the different types of rate limiting?
Rate limiting can be applied based on user, concurrency, location or ID and specific server roles.
What algorithms are used for rate limiting?
Common algorithms include leaky bucket, token bucket, fixed window counter, sliding log and sliding window.


