

In our recent peek into three companies’ CI/CD pipelines, Vulcan Cyber CTO Roy Horev told us his team was experimenting with a method called “deployment trains.” They’d borrowed the setup from Monday.com, a no-code platform where teams can build their own workflow apps.
“I really admire their engineering department, and I thought we should try that out,” Horev said.
“Trains” mean different things to different developers. Here, they refer to long sprints ending in arbitrary release days. Here, they refer to self-organizing deployment pods.
Monday’s version is distinct — trains describe the company’s scheduled deployments, every hour on the hour. If developers want to deploy on an upcoming train, they send their commits to a staging environment. If each commit is good to go, the train packages that deployment and takes it from pre-production to production. The testing and deployment process takes about 20 minutes, which leaves 40 minutes before the next deployment to fix anything that breaks.
It’s a middle-path between manual deployment and full CI/CD, and it significantly cuts down on confusion and broken main branches, according to Horev.
“I think a train is a perfect way to describe it,” he said. “If you’re late to the train, you’re not going anywhere, but if you’re on the train, we know exactly who you are, what you did and where it’s going.”
Trains like this can improve visibility, and, if Vulcan Cyber’s experience is any indication, the quality of the entire deployment process.

Deployment Trains Squash Confusion Around When to Ship Code
When Tel Aviv-based Monday.com leapt from 20 engineers to about 100 in one year, the growth created hang-ups for the team’s deployment process. The pipeline was automated, but developers launched the process manually. They often needed to synchronize their deployments with each other, which got tricky. Even eating lunch became a potential problem.
“People would go to lunch and miss the opportunity to click deploy, and it would make the entire R&D team very frustrated,” Monday.com infrastructure engineer Dan Ofir said.
“People would go to lunch and miss the opportunity to click deploy.”
Moreover, the lack of visibility into the deployment process could turn frustrations into actual arguments.
“Are you sure it just deployed?” one engineer would ask. “I don’t see my code in there and I committed it two minutes ago.”
“No,” another would answer, “You must have committed it four minutes ago because I deployed three minutes ago.”
Then they’d crowd around a keyboard and check GitHub for the exact moment the server went up and maybe descend into arguments about who was supposed to inform whom about the timing of the next deployment, Ofir said.
It was nobody’s fault. Timing manual deployments with such a large team felt impossible, and converting to a full CI/CD process wasn’t ideal with the company’s existing tech stack and blue/green deployment set-up, in which two identical production environments — one live, one idle — take turns serving traffic and running tests.
Something had to give. By good fortune, one of Ofir’s coworkers had come from a job at SaaS company Samanage, which used deployment trains. The closer Ofir looked, the better the approach seemed, so he and his team set up a developer-facing deployment dashboard.
“We really love dashboards,” Ofir said. “Our offices are stacked with dashboards. Everywhere you look, you will find some kind of dashboard.”
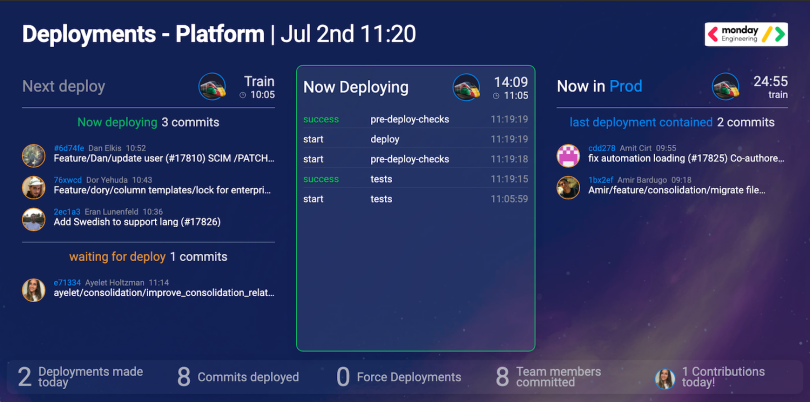
Monday organized its deployments into scheduled trains, and the dashboard showed everyone when the next train was leaving, the status of tests, which tests failed and which features on a particular train were committed to the main branch. Each test was tagged to a specific team, and engineers on that team would be notified if their commits failed to pass.
The train set-up came with three main benefits. First, the boost in visibility did away with any squabbles about when deployments happened, and which code got committed.
“For a DevOps or infrastructure team, this is their bread and butter. It’s perfect for them.”
Second, the trains marked the end of guessing which deployments contained which bugs. When developers triggered their own deployments, no one knew exactly how many were happening each day. So, when a bug was discovered and someone instigated a rollback to get it out of production, there was no guarantee the targeted deployment would actually be the one containing the bug.
“We’d get stuck with the bug in production,” Ofir said. “We’d need to do what’s called a ‘roll forward’ to fix this and deploy again, and users get hurt that way.”
Now, if a bug shows up, developers know exactly which train last deployed, and which commits it carried.
Last, deployment trains virtually eliminated manual overrides, or forced deployments. The trains leave often enough and move quickly enough that developers almost never need to bypass the tests and push something into production manually. When they do, the entire team is alerted, which disincentivizes anyone from mashing the deploy button to avoid the wait.
When Monday.com first switched to deployment trains, the company thought it’d just be a quick stop on the track to a full CI/CD pipeline. But 10 months in, the company has no plans to change its approach, Ofir said.
Instead, the team is thinking about how to make deployment trains better. Developers want it to be faster, of course. Other aspirations include parallel testing and deployment, a viewable history so developers can roll back to older versions of the main branch, and specifying the tagged tests further to pinpoint problematic lines of code and alert the exact developer responsible.
“I really think that if developers understood the limits and benefits of [deployment trains], they would love the process,” Ofir said. “And, obviously, for a DevOps or infrastructure team, this is their bread and butter. It’s perfect for them.”

Merge Trains at GitLab Prevent Broken Main Branches
Monday.com isn’t the only organization using a train image to describe its deployment workflow, but not all trains look — or function — the same.
Monday’s deployment trains help improve visibility and keep buggy code out of production by bundling commits into scheduled deployments. As train analogies go, this one’s like a train platform: planned departures at predictable intervals.
GitLab’s merge train feature, meanwhile, is more like the train cars. When developers enable this feature and make a merge request, the request joins a queue. Imagine four requests in a row: A, B, C and D.
Each request in the queue — up to 20 requests — has its own pipeline that runs concurrently with the others. The pipelines assume each request will be accepted. So, request A is tested against the main branch. Request B is tested against the main plus A. Request C is tested against the main plus A plus B, and so on. If a test determines that a particular request would break the main branch, it’s dropped from the queue, and all the requests behind it restart their pipelines. (In other words, if B breaks, it simply disappears, and requests C and D are re-tested against the updated train in their concurrent pipelines.)
With this approach, the post-merge result of each request gets validated before the merge even happens, so main branches stay “green,” or free from broken components.

The merge train feature was spearheaded by GitLab CEO Sid Sijbrandij last year and implemented with GitLab 11.8 (the company is currently on release 13.1). The feature is currently in the “viable” stage, which means it’s heavily used among GitLab’s 1,200 employees but hasn’t been formally tested with external users.
According to senior product manager Orit Golowinski, the feature significantly cuts down on time “wasted” trying to fix broken main branches.
“I can tell you from my previous company, we were working on feature branches and every time we needed to merge back to master, there was such a long gap between what the developer was working on and what the master was that it would take days just to merge it — not to talk about all the buggy code that was in there until we figured everything out,” she said.
Furthermore, Golowinski added, as the pace of development gets faster, developers juggle more features at a given time. That makes their work more likely to veer farther from main branches, which increases the likelihood of bugs and breaks. Checking all those merges manually — or rolling back buggy deployments after the fact — could be too much for some development shops.
“[The merge train] catches something that would break the pipeline before deployment and drops it out of the train, so there’s no need to prepare for rollbacks,” GitLab senior product manager Thao Yeager said. “And it proactively allows the engineer who checked in that problematic merge request a chance to remedy the problem and then enter that merge request back into a new slot at the end of the train.”
“This isn’t just a little, small feature. This is a game-changer.”
The merge train feature is a favorite among GitLab’s internal developers, Golowinski and Yeager said, but the team is far from finished building on it. (And since GitLab is an open-core company, a business that sells open-source-produced software, outside developers can contribute as well.)
Like Monday.com, GitLab wants to dial in the system for notifying developers when something in the train goes awry. They also want to improve visibility into the pipelines, so developers can eventually see when a particular merge request was added and what position it’s at in the train, as well as the train’s merge history.
Maybe most crucially, they want to add what they’re calling “fast-forward merge.” That will ensure particularly fast-merging requests don’t override older requests as the pipelines run concurrently.
As the feature progresses down GitLab’s maturity continuum from “viable” to “complete” to — hopefully — “lovable,” Golowinski said she’s confident it will be a fit for “any shop.”
“It scales beautifully when there is a huge group of engineers, but it’s also useful when you only have three and you don’t want to break each other’s changes.
“This isn’t just a little, small feature,” she said. “This is a game-changer.”


