

Contrastive learning is an emerging technique in the machine learning field that has gained significant attention in recent years. It involves training a model to differentiate between similar and dissimilar pairs of data points by maximizing their similarity within the same class and minimizing it between different classes.
What Is Contrastive Learning?
Contrastive learning involves training a model to differentiate between similar and dissimilar pairs of data points by maximizing their similarity within the same class and minimizing it between different classes.
This technique has a wide range of applications, including computer vision and natural language processing. One of the key advantages of contrastive learning is its ability to learn from unlabelled data, making it highly scalable and useful for pre-training.
However, this technique presents several challenges, including finding suitable hard negatives, selecting the right batch size and minimizing false negatives. We will explore the concept of contrastive learning, its use cases, the contrastive loss function and some considerations that need to be taken into account while implementing this contrastive learning.
What Is Contrastive Learning?
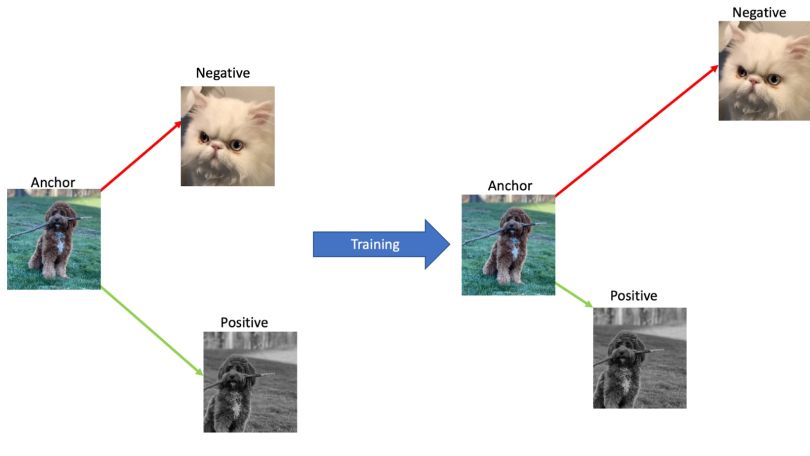
The idea behind contrastive learning is that we have a reference, or “anchor” sample, a similar or “positive” sample, and a different or “negative” sample. We try to bring positive samples close to the anchor sample in an embedding space while pushing negative samples far apart.
In the computer vision example, we might try to learn an encoder (e.g. a convolutional neural net) that pushes positive image embeddings together and negative embeddings apart. A positive sample could be an image from the same class as the anchor or an augmented version of the anchor image, while the negative sample is a completely different image (usually from a different class).
In the following example, we bring embeddings from the same dog image closer together and push the embedding from the cat image further away:
Contrastive Learning Use Cases
Contrastive learning is most notably used for self-supervised learning, a type of unsupervised learning where the label, or supervisory signal, comes from the data itself. In the self-supervised setting, contrastive learning allows us to train encoders to learn from massive amounts of unlabeled data.
Specifically, in self-supervised contrastive learning, for any given anchor image, we create a positive sample by augmenting the original image. We create a negative sample by simply taking another random image from our batch. The above drawing is an example of self-supervised contrastive learning using color and crop-and-resize augmentations.
Contrastive learning has also been used in the supervised setting. Recently, supervised contrastive learning was shown to slightly outperform the standard cross-entropy loss for image classification. In supervised contrastive learning, positive samples come from images with the same class label, while negatives come from images with different class labels.
Contrastive Loss Function
The most common formulation, the InfoNCE loss, for contrastive learning is given by the following equation:
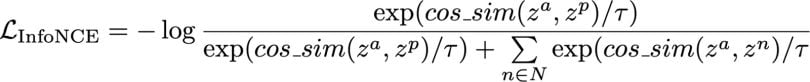
In this equation, the anchor, positive, and negative embeddings are given by za, zp, and zn. Note that we have one positive sample and multiple negatives (N), as is commonly the case in the self-supervised setting. In the supervised setting we generalize the equation to include multiple positive samples. The cos_sim function is the vector cosine similarity function.
Note that we are trying to maximize the cosine similarity between za and zp, bringing them closer together. The opposite is true for za and zn. We also have a temperature hyperparameter , which controls the amount of penalty for harder negative samples. A lower temperature places a greater penalty on harder negatives. Common values are around 0.07 or 0.1.
Considerations for Contrastive Learning
There are a few practical considerations to keep in mind when using contrastive learning, especially for self-supervised learning.
First is the batch size. As in most ML applications, a larger batch size is better. In contrastive learning, a larger batch size gives you more diverse and difficult negative samples which is crucial for learning good representations. Batch size is often limited by the amount of GPU memory, so some adaptations of contrastive learning like MoCo use a large dictionary queue for negative samples which is much larger than a typical mini-batch.
Another important consideration is the quality of the negative samples. We want hard negatives, but not false negatives. Hard negatives improve the representation quality learned by contrastive learning; if negatives are too easy, then an encoder may already be able to discriminate the pairs without training.
However, we want to avoid “false negatives” or images of the same object that are considered as negatives simply because they are different images in the unlabeled dataset. Several more advanced methods, beyond the scope of this article, have focused on sampling harder negatives or attempting to avoid false negatives with a modified contrastive loss.
Finally, as with other deep learning techniques, there are a few more considerations that are important for contrastive learning. The type of augmentations used are very important. Typically, a mix of augmentations like color shift, crop-and-resize, and blurring has shown to work well for contrastive learning (see SimCLR). Additionally, tuning hyperparameters such as the learning rate, temperature and encoder architecture is often necessary to improve representation quality.